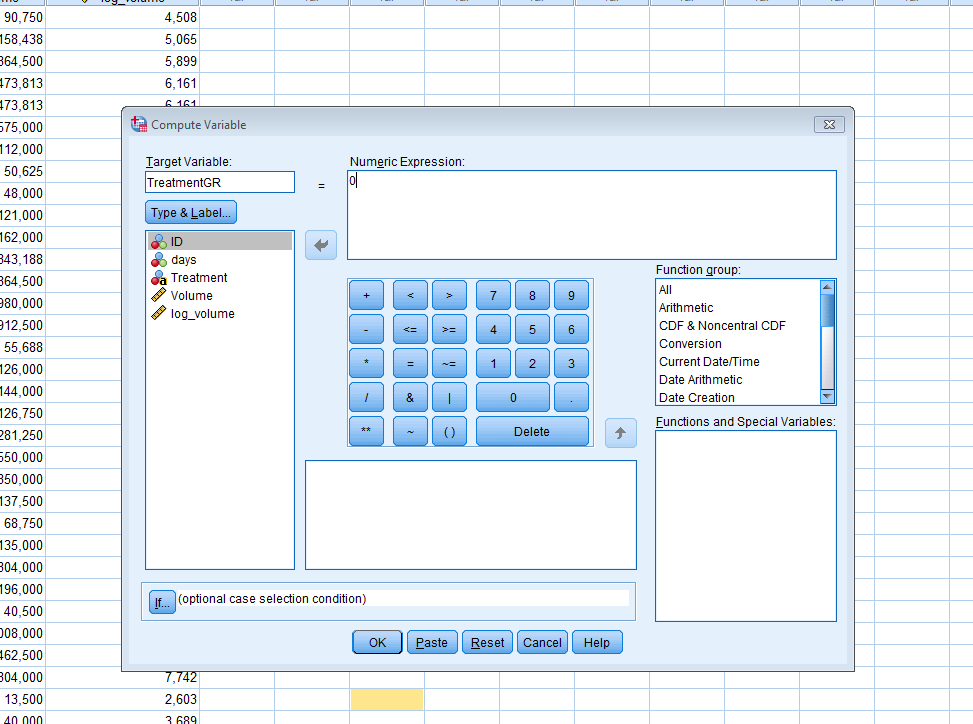
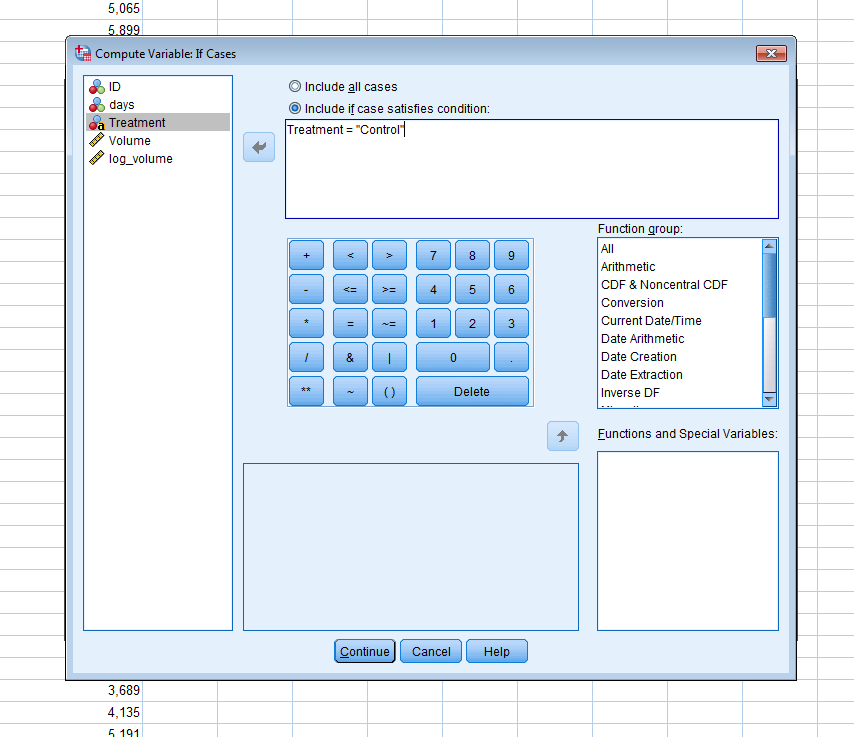
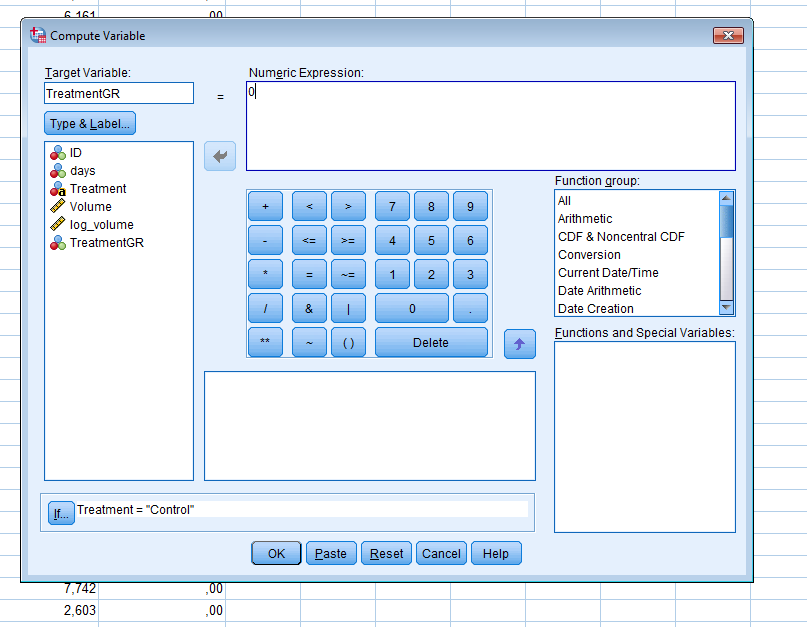
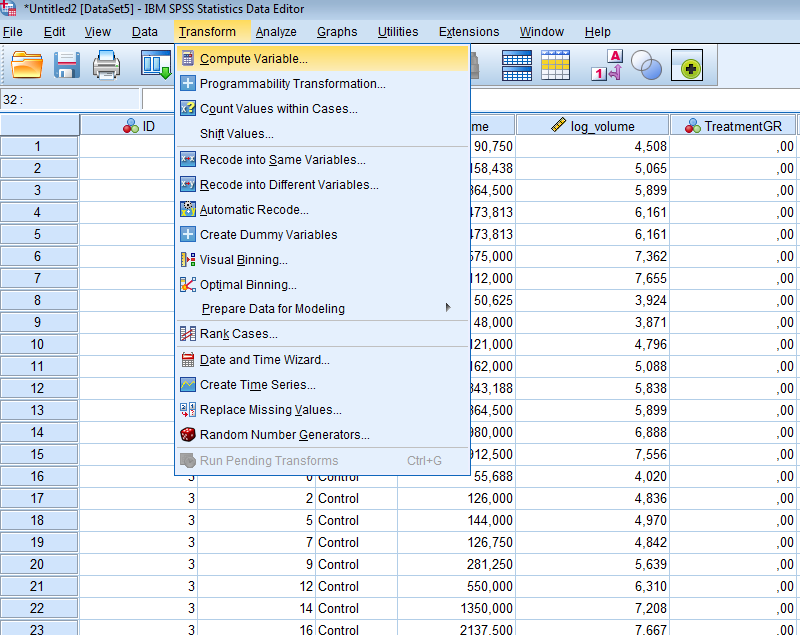
An experiment is conducted to answer a particular research question, for instance,
to investigate whether the outcome after a new treatment differs from the outcome after the standard treatment,
i.e. whether there is an effect of the new treatment. The research question is typically framed into a null hypothesis
(e.g., there is no treatment effect) and an alternative hypothesis (e.g., there is a treatment effect). The answer to the
research question is based on a statistical hypothesis test, which either leads to the rejection of the null hypothesis or not.
The statistical test is designed to generally reflect the true state of nature, but there is a chance for erroneous decisions.
A researcher can make two types of correct decisions and two types of errors, which is shown in the table below.
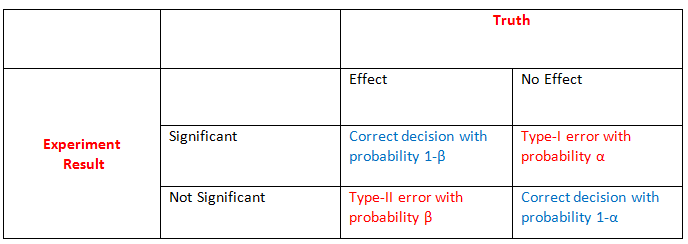
The effect either exists or not in nature, while the result of the statistical analysis is either significant or non-significant. Therefore, based on the statistical analysis,
a researcher either makes a correct inference about the effect or a false one. The type 1 error (\(\alpha\)) is the probability of finding an
effect, i.e. rejecting the null hypothesis of no effect, when it does not exist. It is also called the significance level of a test. The type 2 error (\(\beta\)) is the probability of not finding
an effect, i.e., not rejecting the null hypothesis of no effect, when the effect exists. The type 1 error is the probability of a false positive finding, while the type 2 error is the probability
of a false negative finding. Complements of the two probabilities, 1-\(\alpha\) and 1-\(\beta\) , are probabilities of correctly not finding an effect
(true negative finding) and correctly finding an effect (true positive finding), respectively. The latter probability, 1- \(\beta\), is also called
the statistical power of a test. The value of \(\alpha\) is usually fixed at 0.05. The value of beta decreases with increasing effect size and sample size.
If there is a true effect of a treatment, researchers would like to detect it with high probability.
A power level of 0.8 or 0.9 is usually considered sufficient. For illustration, if 100 experiments are conducted with an existing true effect and
each experiment has a power of 0.8 (i.e., 80%), the statistical analyses would be significant for 80 experiments (and result in rejection of the
hypothesis of no effect), while 20 experiments would yield a non-significant result of the statistical test, i.e., the true effect would be missed
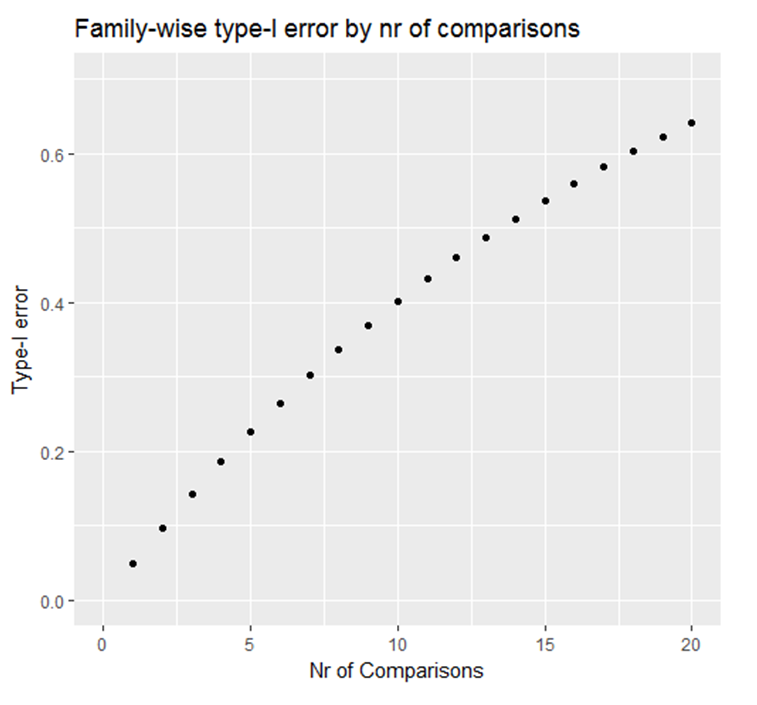
(false negative finding). On the other hand, if none of the 100 experiments is based on a true effect, and a significance level of \(\alpha\)=0.05 (i.e., 5%)
is used, then the statistical analysis of 5 experiments would be expected to be statistically significant (p<0.05), i.e., reflecting false positive
(or chance) findings.
Statistical power is a measure of confidence to detect an effect (i.e., a significant result) if it truly exists. The power depends on the sample size of
an experiment and the magnitude of the effect. During the design phase of an experiment, a researcher can assess how many mice need to be included in
order to detect a true effect with sufficient probability. This assessment is important because an underpowered experiment (too few mice) can miss an
effect that truly exists. An overpowered experiment (too many mice) can detect an effect that truly exists but is so small that it is not of practical
relevance. In both situations, resources spent on an experiment, such as money, time or animals' lives are wasted.
* More power increases the chance of a significant result.
* More power increases the chance of replicating prior findings, if true.
* More power increases the confidence about the results, either significant or not.
So far, we assumed that a true effect does or does not exist. In reality, this is unknown. Let R be the probability that a true effect exists for a particular experiment or,
in a large number of experiments (e.g., all experiments done in a career), the proportion of experiments with a true effect.
The table of possible decisions based on statistical tests is then given by:
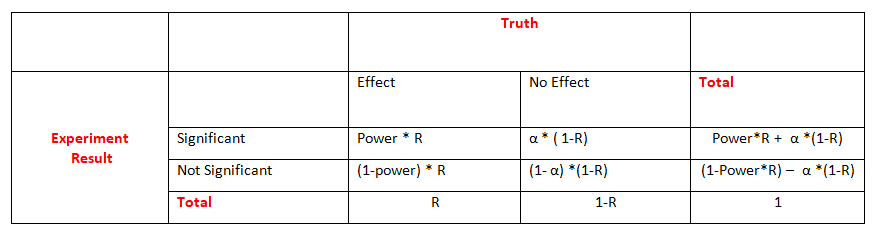
Assume a scientist develops and tests hypotheses so that a true effect exists (i.e., the null hypothesis is wrong) for half of her experiments (R=0.5).
If she chooses the sample sizes of 100 experiments so that power is 80%, she is expected to obtain significant tests for 40 of the 50 experiments with a true effect
(i.e., reject 40 of the 50 wrong null hypotheses) and miss the effect for the remaining 10 experiments (i.e., not reject 10 of the 50 wrong null
hypotheses). If power is 50%, only 25 of the 50 true effects will, on average, be identified. For each experiment, four important measures are considered:
1.$$\text{True positive rate} = \frac{Power*R}{Power*R + (1-Power)*R} = Power$$The probability of a significant result if the effect truly exists.
2.$$\text{True negative rate} = \frac{(1-\alpha)*(1-R)}{(1-\alpha)*(1-R) + \alpha*(1-R)} = 1-\alpha$$The probability of a non-significant result if the effect does not exist. It is the complement of the type 1 error \(\alpha\).
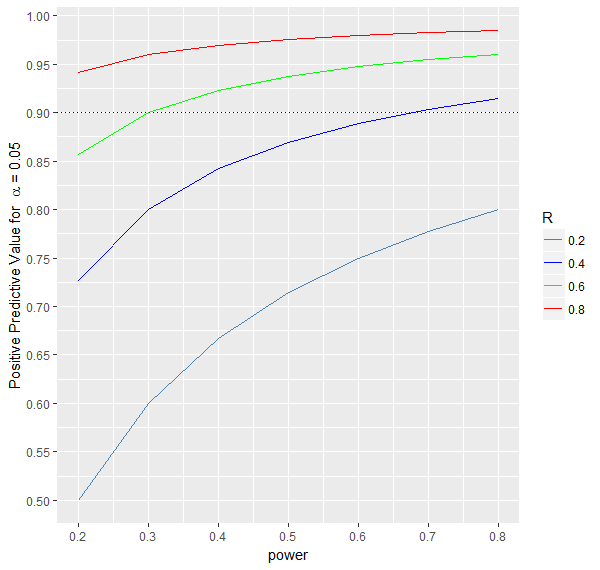
3.$$\text{Positive predictive value(PPV)} = \frac{Power*R}{Power*R + \alpha*(1-R)}$$The probability that the effect exists given a significant result of the statistical test.
As can be seen from the formula and the graph below, this probability increases with increasing power and R.
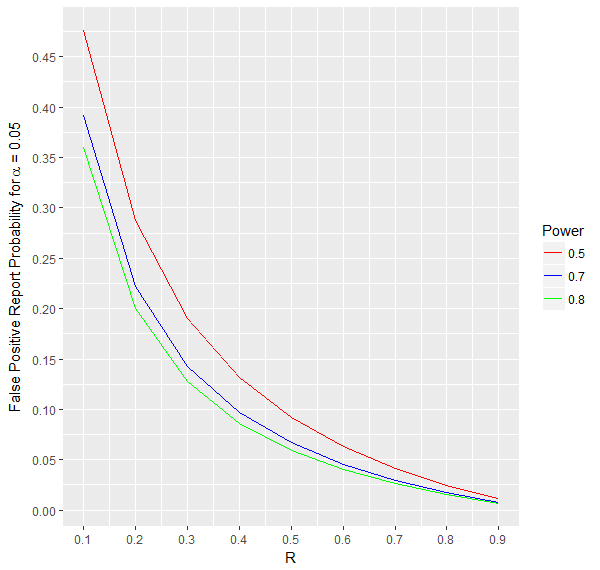
4.$$\text{False Positive Report Probability(FPRP)} = 1-PPV = \frac{\alpha*(1-R)}{Power*R + \alpha*(1-R)}$$The probability that there is no effect if the statistical test is significant.
As can be seen from the formula and the graph below, this probability decreases with increasing power and R.
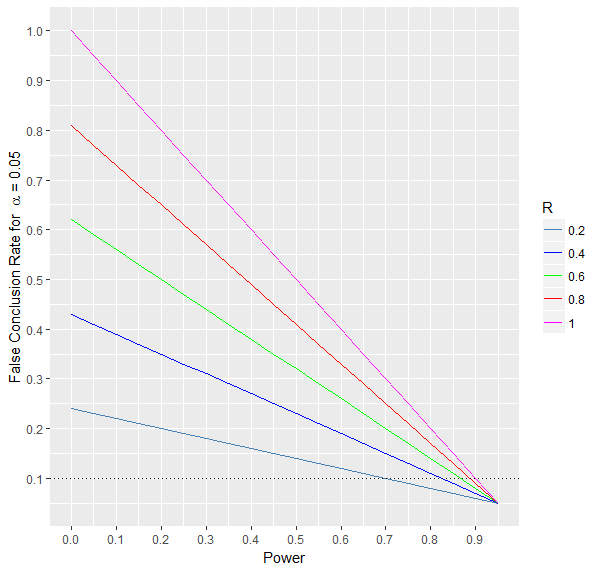
A false conclusion is either making a type 1 or type 2 error. The false conclusion rate can be determined by combining the type 1 and type 2 errors.
As is illustrated in the graph below, this rate decreases with increasing power and decreasing R.
Moreover, when the prior probability of the effect is maximum, i.e., R=1, then the false conclusion rate depends only on the power of the test.
More precisely, it is actually equal to the type 2 error \(\beta\) or equivalently to 1-power. When R = 0, the false conclusion rate is equal to the
type 1 error \(\alpha\) .
For fixed values of \(\alpha\) and power, a higher probability R is associated with more false conclusions. The lower the power,
the higher the influence of R on the false conclusion rate.
Statistical power depends on three factors
To determine the power of an analysis we need firstly to specify the alternative hypothesis, \(H_a\), or in other words,
the effect size that we are interested in detecting. Further, and for most of analyses, power is proportional to the following:
*Effect size : the size of the effect, which can be measured as a difference in mean/median values, survival outcomes,
proportions or growth rates; the bigger the effect size the higher the power
*Sample size : the number of mice included in an experiment; the higher the number of mice the higher the power.
*Significance level(\(\alpha\)) : the type 1 error of a test; the higher the \(\alpha\) the higher the power, but \(\alpha\) is almost always fixed at 0.05.
Power can be calculated based on the three factors. More often, the required sample size is calculated as a function of power,
\(\alpha\) and an estimate of the effect size. Sample size can be calculated for any study design and statistical test.
The correct sample size can be obtained through the following steps:
1. Formulate the research question, i.e., define clearly what the null hypothesis and the alternative
hypothesis of interest are
2. Identify the statistical test to be performed on the data from the experiment
3. Determine a reasonable value for the expected effect size based on substantive knowledge, literature, previous experiments, or select the smallest effect size that is considered as clinically important
4. Select the desired \(\alpha\) level (almost always 0.05)
5. Select the desired power level (mostly 0.8 or 0.9) and calculate the required sample size
Other tabs and links to external sources on this website allow you to calculate the sample size needed in
different situations.